前言
面试的时候,当面试官问你 Java 基础,HashMap 可以说是一个绕不过去的话题,哪怕其他容器(比如 ArrayList,LinkedList)都不问,HashMap 也是不能不问的。不仅仅因为在平时工作中,HashMap 是一个很常用的数据结构,而且由 HashMap 这个数据结构其实能引出很多问题。比如最基本的 get()、put() 方法是吧,get() 就可以聊聊 equals() 方法跟 hashCode() 方法,这算是 Java 基础了吧;稍微升级一下难度,聊聊扩容过程,线程安全问题,进而引申到 ConcurrentHashMap,引申到多线程,引申到 Synchronized 关键字,引申到 JVM 虚拟机是吧,你看这样一联想,整个都串到一起了。
谈谈哈希表的历史
哈希表在工作中是个很常用的数据结构,因为较好的兼顾了修改跟查找的性能。JDK1.0 中最早实现这个数据结构的类是 HashTable,而且更贴心的是这个类是线程安全的。理论上,只要想使用哈希表这个数据结构的的地方,用 HashTable 就肯定不会有问题。但是凡事都是有代价的,在实现了线程安全的同时,其实是极大地牺牲了性能的。简单翻一下 HashTable 的源码,看 get() 跟 put() 两个方法,可以看到这两个方法都被加了synchronized关键字,这也是 HashTable 线程安全的原因。
但是你想,直接把整个对象锁住,这是不是小题大做了,尤其是在单线程的场景下,就比如一个业务请求进来,在这个请求的处理过程中新建了一个哈希表,去对哈希表进行一些操作的时候,每次都上锁是不是过分了?其实就他一个线程操作,根本没必要去上锁,全程绿灯直接操作就行了。所以在 JDK1.2,我们有了一个新的类,HashMap。这个类并不是线程安全的,也意味着在单线程情况下,他没有为了保证线程安全而引入的不必要的开销,所以性能很好。于是,那个时候,没有线程安全要求的,直接使用 HashMap 就行了,有线程安全要求,比如某些全局变量什么的多线程访问的情景,那就直接使用 HashTable。
但其实前面我们也说了 HashTable 实现线程安全的方式十分简单粗暴,直接对整个哈希表加了锁,这就导致在高并发场景下频繁操作哈希表的时候,性能较差。于是在 JDK1.5 里面,并发大师 Doug Lea 为我们带来了 ConcurrentHashMap,通过粒度更细的锁,减少了锁的竞争,从而实现了更好的性能。
HashMap 底层原理
HashMap 的变迁
在不同版本的 JDK 中,HashMap 是在不停优化的。
- 比如 JDK1.6 里面 new HashMap 时,开辟了内存空间,如果不使用,则浪费内存;JDK1.7 里面改成了懒加载,new HashMap 并没有开辟内存空间,节约了内存空间
- 1.8 优化了 hashCode 算法:高 16 位异或(XOR)低 16 位 主要是增加了扰动,减少了哈希碰撞的几率
- 1.8 里面优化了 hash 碰撞较多情况下的性能问题(链表长度限制为 8,过长时会将链表转换为 TreeNode(红黑树))
类继承关系
Java 为数据结构中的映射定义了一个接口 java.util.Map,此接口主要有四个常用的实现类,分别是 HashMap、Hashtable、LinkedHashMap 和 TreeMap,类继承关系如下图所示:
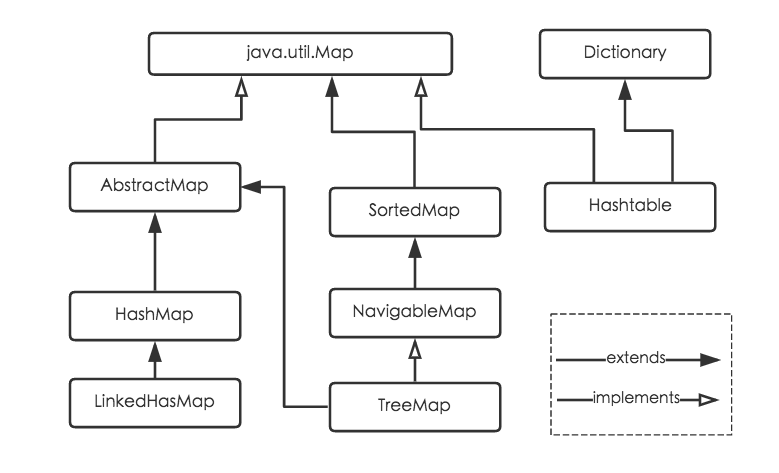
下面简单介绍一下各个实现类的特点:
HashMap:它根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
Hashtable:Hashtable 是遗留类,很多映射的常用功能与 HashMap 类似,不同的是它承自 Dictionary 类,并且是线程安全的,任一时间只有一个线程能写 Hashtable,并发性不如 ConcurrentHashMap,因为 ConcurrentHashMap 引入了分段锁。Hashtable 不建议在新代码中使用,不需要线程安全的场合可以用 HashMap 替换,需要线程安全的场合可以用 ConcurrentHashMap 替换。
LinkedHashMap:LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 Iterator 遍历 LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
TreeMap:TreeMap 实现 SortedMap 接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。如果使用排序的映射,建议使用 TreeMap。在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的 Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常。
对于上述四种 Map 类型的类,要求映射中的 key 是不可变对象。不可变对象是指该对象在创建后它的哈希值不会被改变。如果对象的哈希值发生变化,Map 对象很可能就定位不到映射的位置了。
HashMap 的底层数据结构
其实广义来讲,数据结构只有数组跟链表两种,本质上就是看数据在存储的时候是否连续,其他的各种数据结构,比如栈、队列、跳表、树,都可以用数组或者链表来实现。而 HashMap,算是集中了这两者特点的一种数据结构,在很多地方都会用到。比如 Spring 里面存放各种 bean 用的容器,用的就是 ConcurrentHashMap。
下面插入一张我画的大致的数据结构图:(下述讨论都基于 JDK1.8)
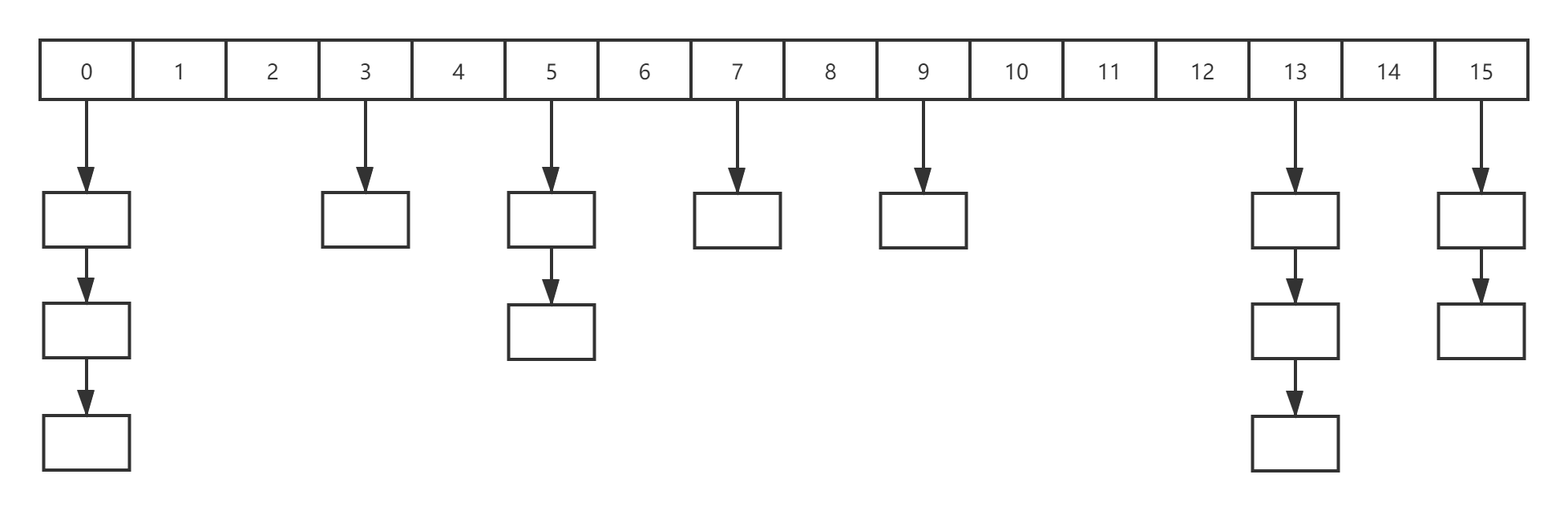
但这张图,其实是有问题的,不知道你发现没,哈哈哈,我后边再讲。如图所示,HashMap 底层的数据结构就是数组 + 链表。
1 | transient Node<K,V>[] table; |
上述代码摘自 JDK 1.8 中 HashMap 部分源码,table 即为我所说的数组,而 Node 即为链表的一个节点,里面有 hash、key、value 以及下一个节点。
下面分别介绍一下 Node 中的各个字段:
- hash:存储的键值对中 key 的 hash
- key:存储的键值对中的 key
- value:存储的键值对中的 value
- next:指向下一个 Node
默认配置常量
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
HashMap 容器初始化的容量为 16,默认负载因子为 0.75,树化阈值为 8,反树化阈值为 6,最小的树化容量为 64。
负载因子
负载因子(LOAD_FACTOR)结合容量(CAPACITY),其实就得到了 HashMap 扩容的一个阈值,大于这个阈值的时候,HashMap 就会进行 resize() 扩容操作。至于负载因子为什么是 0.75,源码里的注释简单提了一嘴,其实就是不说我们也能猜出来。
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put).
其实就是权衡了空间占用跟查找效率,负载因子太高固然节省空间,但查找效率也会因此下降,包括 get 跟 set 等操作。
回到上边那张图,对于初始容量 16,负载因子 0.75 来说,超过 12,也就是图中画的 13 个元素,就会触发扩容,所以我前面说那张图有问题。但当时画的时候随手画的,也懒得改了,就随它去吧。
Hash 算法
1 | static final int hash(Object key) { |
从上述算法可知,HashMap 中可以存放 key 为 null 的值,放在首位。而对于哈希值,是将高 16 位与低 16 位进行异或运算,这样做的目的主要是尽量保证 hash 值的均匀,通过这样一个扰动函数,减小了 hash 冲突的概率。
然后再通过(n - 1) & hash这个 hash 值与数组的长度进行取模运算,决定这个键值对该放入 table 中的哪个 Node 中。
扩容过程
当容量大于阈值的时候,就会触发 HashMap 的扩容操作。扩容操作其实就是新建一个容量是原先数组两倍的新数组,将原先小数组的元素重新哈希到新的数组上。因为容量是 2 的幂,扩容的时候,元素要么在原位置,要么往后移动原来的容量大小的位置,这时候使用的是下面这个算法:
e.hash & oldCap
如果得到的结果为零,则在原位置;反之,则将其向高位移动 oldCap 大小的位置。
哈希冲突
教科书上告诉我们,碰到哈希冲突的时候,一般有两种解决办法:开放定址法跟链表法。
HashMap 选择的是链表法来解决哈希冲突的,也十分好理解。简单来说就是当哈希冲突的时候,将哈希冲突的元素挂到一条链表上,至于查找的时候具体是哪个元素,就需要再去链表上比较查出来了。
HashMap 常用方法
put 流程
- 对 key 的 hashCode() 做 hash 运算,计算 index;
- 如果没碰撞直接放到 table 里;
- 如果碰撞了,以链表的形式存在 table 后;
- 如果碰撞导致链表过长(大于等于 TREEIFY_THRESHOLD),就把链表转换成红黑树 (JDK1.8 中的改动);
- 如果节点已经存在就替换 old value(保证 key 的唯一性)
- 如果 table 满了(超过 load factor*current capacity),就要 resize。
get 流程
- 对 key 的 hashCode() 做 hash 运算,计算 index;
- 如果在 table 里的第一个节点里直接命中,则直接返回;
- 如果有冲突,则通过 key.equals(k) 去查找对应的 Node;
- 若为树,则在树中通过 key.equals(k) 查找,$O(\log n)$;
- 若为链表,则在链表中通过 key.equals(k) 查找,$O(n)$。
链表跟红黑树互转
虽然源码中说了,根据泊松分布,哈希冲突的概率很低。但是如果真碰到一些极端情况,比如写死了 HashCode,那么那个 Node 上的元素过多,是会从链表转换成红黑树的。这里其实有一点就是并不是链表长度达到 8 就会转成红黑树。还有另外一个前提条件,就是整个哈希表容量要大于等于树化阈值,默认的树化阈值是 64,因为如果哈希表容量过小就用红黑树,可能会引起频繁扩容跟链表树化之间的冲突,性能并不一定比链表好。所以,在大容量的哈希表中,最极端的情况也就是通过红黑树来查找元素,这种情况下的算法复杂度是$O(\log n)$,明显好于链表的$O(n)$。
这里其实经常容易被问到的另一个问题就是:为什么用的是红黑树,而不是 AVL 树。
要回答这个问题就要回到这两种数据结构的特点上面。红黑树的查询性能略微逊色于 AVL 树,因为它比 avl 树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的 avl 树最多多一次比较,但是,红黑树在插入和删除上完爆 avl 树,avl 树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于 avl 树为了维持平衡的开销要小得多。所以,对于 HashMap 这种频繁读写的数据结构,选择红黑树相比 AVL 树是更好的选择。
总结
本文简单总结了 JDK 中哈希表这一数据结构的演变,介绍了 HashMap 的一些底层原理和常用方法,里面掺杂了大量个人主观色彩的见解,如果有错误的地方可以留言一起讨论,希望大家都能够有所收获。